Vélo, Sigma Blaze et Impression 3D
Rédigé par dada / 01 décembre 2024 / Aucun commentaire
Mes activités informatiques devenant, à mes yeux, de moins en moins passionnantes à raconter, je me retrouve un peu perdu quant à l'alimentation de ce blog. Je sais que j'ai déjà digressé en parlant films, séries ou encore impression 3D alors permettez-moi de parler vélo.
Je ne sais pas si vous l'avez remarqué mais pas mal de libristes sont aussi des vélotafeurs. Du moins, vu de ma fenêtre Mastodon. Ils et elles ont réussi à me refiler le virus. Bon, il n'en fallait pas beaucoup : mon bout de ville devenant piéton, j'ai vite trouvé très utile et très simple de sauter sur un vélo pour aller un peu partout.
Sigma Blaze
Le Blaze de la marque Sigma est un feu arrière pour vélo. Il a ceci de fabuleux qu'il s'allume quand on rentre dans une sombre et qu'il s'allume quand on freine. Oui, vous avez bien lu : le feu rouge se comporte comme celui de tous les autres véhicules : il s'allume quand on freine. Magie ? Non, un accéléromètre.
Je me demande encore pourquoi l'intégralité des feux de vélo ne propose pas cette simple option. D'un côté, je me demande aussi pourquoi des cyclistes continuent d'utiliser des lumières qui clignotent alors que c'est interdit. Un feu peut être à intensité variable (rouge classique, rouge fort signalant le freinage) mais pas clignotant. Bref.
J'ai acheté ce gadget pour l'ajouter à mon équipement actuel. Problème : je n'ai pas la place sur la tige de ma selle pour deux lumières s'enroulant autour. Mon vénérable MBK Mirage récupéré chez Dynamo n'est pas vraiment prévu pour ce genre d'engins. Qu'à cela ne tienne, j'ai une imprimante 3D et un peu de plastique !
Impression 3D
Il m'aura fallu un pied à coulisse, l'excellent FreeCAD et quelques heures pour réussir à modéliser ça :
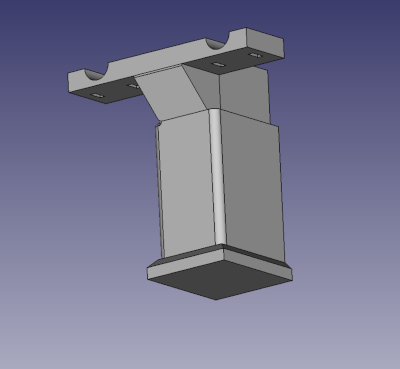
Ce dispositif va se fixer sur les tiges de ma selle à l'aide de de colliers de serrage. Je me suis clairement inspiré de ce que j'ai pu trouver sur Printables. Y'a vraiment des gens avec des idées incroyables chez les makers !
Je peux maintenant enrouler le Blaze sous ma selle et laisser la vielle lumière en dessous, sur la tige, en double éclairage de nuit. J'en suis très content !

N'imaginez pas que la photo ci-dessus représente la première version de support. J'ai fait pas moins de 6 itérations avant d'être plus ou moins satisfait. J'ai d'abord raté les trous des serflex, puis fait une pièce trop fine pour que l'élastique se tende suffisamment autour de la tige, puis décidé de rallonger la tige pour plus de sérénité puis j'ai ajouté une buttée.
J'ai imprimé la pièce en PETG. Pour le moment, ça devrait faire l'affaire. En cas de soucis dus à l'exposition prolongée aux éléments, je la referais en ASA.
Plus tard...
Ce billet ayant maintenant plus de 12 mois d’existence dans mes brouillons, je vous confirme que mon impression est top, qu'elle fait parfaitement son travail et qu'elle est très apprécié sur Printables. Content !