L'alerting avec Prometheus
Rédigé par dada / 02 août 2018 / 4 commentaires
Depuis le temps que je devais l'écrire, ce billet, le voici : comment mettre en place un système d'alerting avec Prometheus !
Pour celles et ceux qui ne sont pas familiers avec ce vocabulaire : l'alerting est une notion d'administrateur système qui consiste à prévenir les équipes en charge du bon fonctionnement d'un service qu'il est en train de se casser la figure. Ou qu'il s'est déjà vautré.
En avant-propos, je vous invite à aller faire un tour du côté de mes différents billets sur Prometheus.
L'alerting, c'est une brique en plus
Prometheus est une bête idiote, les exporters sont des bêtes idiotes, Grafana est une bête idiote, l'alerting est lui aussi une bête idiote. Pour le faire fonctionner, à la manière d'un exporter, il vous faut installer l'Alertmanager.
L'installation de l'Alertmanager est identique à celle des autres exporter : téléchargez le binaire ou le conteneur Docker, lancez tout ça en lui passant en paramètre son fichier de configuration.
Toujours comme un simple exporter, ou presque, faites comprendre à Prometheus qu'il est là en ajoutant ces quelques lignes dans prometheus.yml, en dessous de la configuration globale :
alerting:
alertmanagers:
- static_configs:
- targets:
- localhost:9093
scheme: http
timeout: 10s
N'oubliez pas de reload la configuration de Prometheus :
curl -X POST http://localhost:9090/-/reload
Configurer la détection des problèmes
Les alertes se présentent sous forme de fichiers que vous allez placer dans le répertoire rules/ de Prometheus :
root@server /etc/prometheus/rules # ls
memory up
Il va ensuite falloir les déclarer dans Prometheus :
# Load and evaluate rules in this file every 'evaluation_interval' seconds.
rule_files:
- '/etc/prometheus/rules/up'
- '/etc/prometheus/rules/memory'
Pour faire simple et rapide, voici des exemples d'alertes qui pourraient vous servir :
- Service disponible
ALERT InstanceDown
IF up == 0
FOR 1m
LABELS { severity = "page" }
ANNOTATIONS {
summary = "Instance {{$labels.instance}} is down",
description = "{{$labels.instance}} of job {{$labels.job}} has been down for more than 1 minutes"
}
- L'utilisation de la RAM
ALERT MemoryUsage
IF ((node_memory_MemTotal-node_memory_MemFree-node_memory_Cached)/(node_memory_MemTotal)*100) > 95
FOR 10m
LABELS { severity = "warning" }
ANNOTATIONS {
summary = "Instance {{$labels.instance}} is in danger",
description = "RAM of {{$labels.instance}} has been too used for more than 10 minutes"
}
Avant de vous lancez dans le copier/coller du code exposé ci-dessus, prenez le temps de lire les quelques lignes suivantes :
- ALERT : il s'agit d'un nom arbitraire que vous donnez à votre alerte
- IF : c'est la condition qu'il faut respecter pour déclencher l'alerte
- FOR : la durée pendant laquelle le IF doit être valide
- LABEL : ça permet de donner un poids à votre alerte (osef, warning, critical, etc)
- ANNOTATIONS : ce que vous voulez afficher quand l'alerte est déclenchée
Normalement, à ce niveau là, vous avez un Alertemanager capable de
détecter si vous avez des soucis de RAM ou si vos serveurs/services sont
fonctionnels ou HS. C'est bien beau, mais ça ne vous réveillera pas en
cas de pépin.
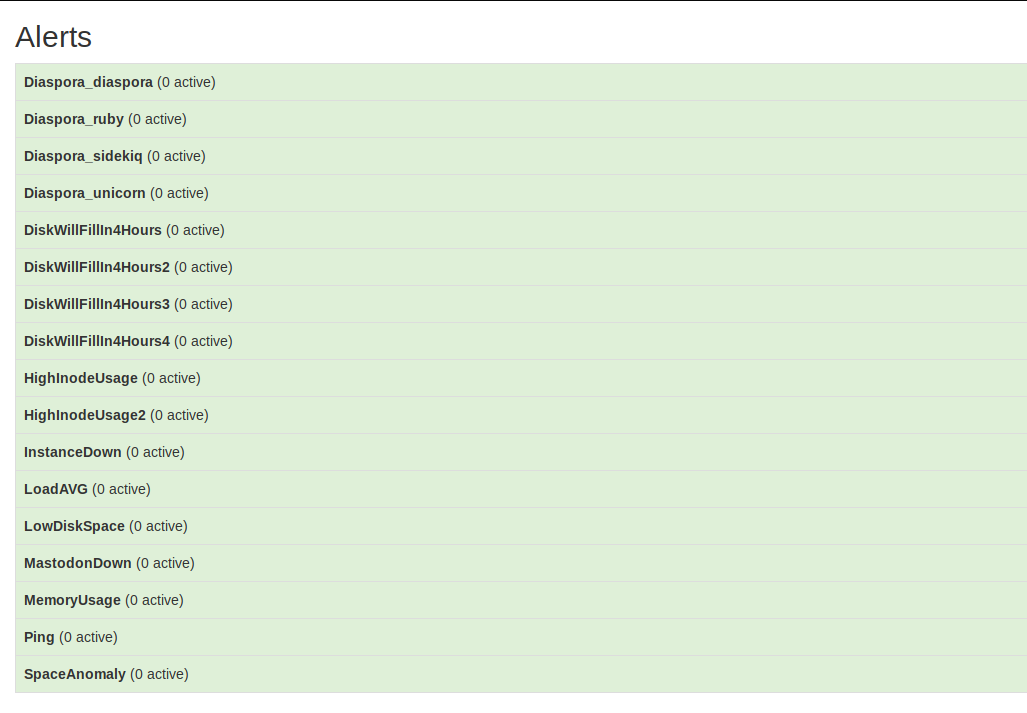
Un rapide tour sur l'interface web de Prometheus devrait vous le confirmer. En exemple, voici la liste des alertes que j'utilise :
Configurer l'envoi d'emails d'alerte
Le fichier de configuration que vous passerez en paramètre au lancement de l'Alertmanager doit lui dire que faire quand une alerte est détectée. Il est possible de lui dire de vous envoyez un message sur Telegram, Mattermost, ou, simplement, de vous envoyer un mail. C'est la solution la plus simple, alors allons-y.
Les possibilités étant énormes, je ne vais vous proposer qu'un exemple de configuration simple :
global:
smtp_smarthost: 'localhost:25'
smtp_from: 'alertmanager@mon.email'
route:
receiver: 'team-mails'
group_wait: 30s
group_interval: 5m
repeat_interval: 3h
receivers:
- name: 'team-mails'
email_configs:
- to: 'ladestination@email.mail'
Avec cette configuration, vous allez recevoir un mail en cas de souci. Sans intervention de votre part, le mail sera renvoyé au bout de 3h.
Cette conf est très simple. Je n'explique pas tout. Juste, elle marche. Si vous souhaitez en savoir plus, comme l'organisation de groupes qui recevront des alertes spécifiques ou la gestion des "warning" ou des "critical", je vous encourage à prendre un peu de temps pour lire l'exemple assez complet qu'on peut trouver par ici.
Et voilà ! Je suis loin d'avoir fait le tour des possibilités de Prometheus mais les différents billets que vous trouverez sur ce blog devraient vous permettre de mettre les doigts dedans et de vous en sortir.
Des bisous !