Rook pour gérer le système de fichiers
Rédigé par dada / 08 novembre 2018 / 4 commentaires

Perdu ? Retrouvez les épisodes précédents :
Un cluster k8s, c'est presque "out-of-the-box" quand on veut s'en servir pour lancer des conteneurs qui n'amènent avec eux qu'un traitement. En gros, votre conteneur contient un script python qui va afficher 42 fois le message "toto" et mourir. C'est un exemple idiot, mais ce n'est pas un détail.
Dans le cadre de ce tuto qui me sert à préparer la migration de ce blog dans un cluster k8s, j'ai besoin de pouvoir stocker le contenu de mes billets quelque part. Le mettre dans un conteneur est une aberration et sera synonyme de perte de données quand celui-ci mourra.
Pour m'en sortir, on m'a parlé de Rook.io, un système de cluster Ceph intégré à Kubernetes. On va voir comment s'en servir maintenant.
Installer Rook
Installer les dépendances
Il va falloir installer des paquets sur vos membres du cluster. À l'exception du Master.
apt-get install ceph-fs-common ceph-common
Récupérer le binaire RBD
cd /bin
sudo curl -O https://raw.githubusercontent.com/ceph/ceph-docker/master/examples/kubernetes-coreos/rbd
sudo chmod +x /bin/rbd
rbd #Command to download ceph images
On va partir sur la version beta de l'outil. C'est la plus stable.
Ajouter le dépôt Rook dans Helm
dada@k8smaster:~$ helm repo add rook-beta https://charts.rook.io/beta
"rook-beta" has been added to your repositories
Récupérer Rook
À la manière de APT :
dada@k8smaster:~$ helm install --namespace rook-ceph-system rook-beta/rook-ceph
NAME: torrid-dragonfly
LAST DEPLOYED: Sun Nov 4 11:22:24 2018
NAMESPACE: rook-ceph-system
STATUS: DEPLOYED
Le message est bien plus long. Je vous invite à prendre le temps de le décortiquer pour y repérer les infos intéressantes.
On peut y récupérer la commande pour valider la présence du pod Operator :
dada@k8smaster:~$ kubectl --namespace rook-ceph-system get pods -l "app=rook-ceph-operator"
NAME READY STATUS RESTARTS AGE
rook-ceph-operator-f4cd7f8d5-zt7f4 1/1 Running 0 2m25
On y trouve aussi les pods nécessaires au cluster dans nos différents nodes :
dada@k8smaster:~$ kubectl get pods --all-namespaces -o wide | grep rook
rook-ceph-system rook-ceph-agent-pb62s 1/1 Running 0 4m10s 192.168.0.30 k8snode1 <none
rook-ceph-system rook-ceph-agent-vccpt 1/1 Running 0 4m10s 192.168.0.18 k8snode2 <none>
rook-ceph-system rook-ceph-operator-f4cd7f8d5-zt7f4 1/1 Running 0 4m24s 10.244.2.62 k8snode2 <none>
rook-ceph-system rook-discover-589mf 1/1 Running 0 4m10s 10.244.2.63 k8snode2 <none>
rook-ceph-system rook-discover-qhv9q 1/1 Running 0 4m10s 10.244.1.232 k8snode1 <none>
On a la base ! Vous devriez avoir un agent et un discover par node. L'operator, lui, reste tout seul.
Création du cluster
Maintenant que Rook tourne, il lui faut lui faire comprendre que nous voulons un cluster qui va bien pour nos volumes.
Je reprends ci-dessous l'exemple de la documentation : ça marche bien comme ça.
#################################################################################
# This example first defines some necessary namespace and RBAC security objects.
# The actual Ceph Cluster CRD example can be found at the bottom of this example.
#################################################################################
apiVersion: v1
kind: Namespace
metadata:
name: rook-ceph
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: rook-ceph-cluster
namespace: rook-ceph
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: rook-ceph-cluster
namespace: rook-ceph
rules:
- apiGroups: [""]
resources: ["configmaps"]
verbs: [ "get", "list", "watch", "create", "update", "delete" ]
---
# Allow the operator to create resources in this cluster's namespace
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: rook-ceph-cluster-mgmt
namespace: rook-ceph
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: rook-ceph-cluster-mgmt
subjects:
- kind: ServiceAccount
name: rook-ceph-system
namespace: rook-ceph-system
---
# Allow the pods in this namespace to work with configmaps
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1beta1
metadata:
name: rook-ceph-cluster
namespace: rook-ceph
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: rook-ceph-cluster
subjects:
- kind: ServiceAccount
name: rook-ceph-cluster
namespace: rook-ceph
---
#################################################################################
# The Ceph Cluster CRD example
#################################################################################
apiVersion: ceph.rook.io/v1beta1
kind: Cluster
metadata:
name: rook-ceph
namespace: rook-ceph
spec:
cephVersion:
# For the latest ceph images, see https://hub.docker.com/r/ceph/ceph/tags
image: ceph/ceph:v13.2.2-20181023
dataDirHostPath: /var/lib/rook
dashboard:
enabled: true
storage:
useAllNodes: true
useAllDevices: false
config:
databaseSizeMB: "1024"
journalSizeMB: "1024"
On apply tout ça :
kubectl create -f cluster.yaml
Si tout s'est bien passé et que vous avez patienté quelques minutes, voici ce que vous devriez avoir maintenant :
dada@k8smaster:~/rook$ kubectl get pods -n rook-ceph -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE
rook-ceph-mgr-a-5f6dd98574-tm9md 1/1 Running 0 3m3s 10.244.2.126 k8snode2 <none>
rook-ceph-mon0-sk798 1/1 Running 0 4m36s 10.244.1.42 k8snode1 <none>
rook-ceph-mon1-bxgjt 1/1 Running 0 4m16s 10.244.2.125 k8snode2 <none>
rook-ceph-mon2-snznb 1/1 Running 0 3m48s 10.244.1.43 k8snode1 <none>
rook-ceph-osd-id-0-54c856d49d-77hfr 1/1 Running 0 2m27s 10.244.1.45 k8snode1 <none>
rook-ceph-osd-id-1-7d98bf85b5-rt4jw 1/1 Running 0 2m26s 10.244.2.128 k8snode2 <none>
rook-ceph-osd-prepare-k8snode1-dzd5v 0/1 Completed 0 2m41s 10.244.1.44 k8snode1 <none>
rook-ceph-osd-prepare-k8snode2-2jgvg 0/1 Completed 0 2m41s 10.244.2.127 k8snode2 <none>
Créer le système de fichiers
Le cluster est en place, mais rien ne nous permet de l'utiliser. On va remédier à ça en lui assignant un système de fichiers. Pour l'exemple, j'ai choisi la méthode dite Block Storage. Elle permet de mettre en place des Persistent Volumes (PV) qui pourront être utilisés par un seul pod à la fois. S'il vous faut plusieurs pods accédant à un PV, dirigez-vous vers le Shared File System.
Pour que ça marche, créez la configuration de la StorageClass :
apiVersion: ceph.rook.io/v1beta1
kind: Pool
metadata:
name: replicapool
namespace: rook-ceph
spec:
replicated:
size: 3
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: rook-ceph-block
provisioner: ceph.rook.io/bloc
parameters:
pool: replicapool
clusterNamespace: rook-ceph
On l'applique :
kubectl create -f storageclass.yaml
On est bon pour le système de fichiers !
On ne va pas créer de pod s'en servant pour le moment. Si vous y allez, vous ne pourrez rien en tirer puisque vous ne pouvez pas encore accéder à votre cluster depuis l'extérieur. C'est la prochaine étape.
Le Dashboard Ceph
Si vous avez pris le temps de lire la configuration du cluster proposée un peu plus haut, vous devriez avoir vu que le Dashboard est activé dans le yaml. Comme pour Kubernetes, Rook intègre un dashboard pour y voir un peu plus clair.
Il est "enable", mais pas activé. Corrigeons ça à l'aide en créant le fichier dashboard-external.yaml :
dada@k8smaster:~/rook$ cat dashboard-external.yaml
apiVersion: v1
kind: Service
metadata:
name: rook-ceph-mgr-dashboard-external
namespace: rook-ceph
labels:
app: rook-ceph-mgr
rook_cluster: rook-ceph
spec:
ports:
- name: dashboard
port: 7000
protocol: TCP
targetPort: 7000
selector:
app: rook-ceph-mgr
rook_cluster: rook-ceph
sessionAffinity: None
type: NodePort
Récupérez le port exposé :
dada@k8smaster:~/rook$ kubectl -n rook-ceph get service | grep Node
rook-ceph-mgr-dashboard-external NodePort 10.99.88.135 <none> 7000:31165/TCP 3m41s
Et vous devriez pouvoir joindre le dashboard en utilisant l'IP du master et le port qui va bien : 31165 dans mon cas.
Si tout va bien, vous devriez pouvoir vous promener dans une page web qui ressemble à ça :
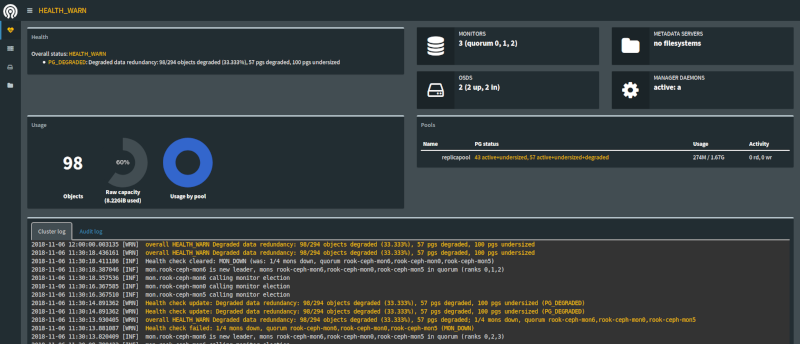
Considérations
La gestion du système de fichiers que je vous propose n'est pas sans risque. Les volumes que vous allez créer doivent être configurés sérieusement. Les exemples que vous aller trouver par-ci par-là vous permettront d'avoir un stockage dans votre cluster k8s, certes, mais rendront sans doute vos volumes dépendants de vos pods. Si vous décidez de supprimer le pod pour lequel vous avec un PVC, le PV disparaîtra, et vos données avec.
Prenez le temps de bien réfléchir et de bien plus étudier la question que ce que je vous propose dans mes billets avant de vous lancer dans une installation en production.