Kubernetes en multi-master sur du baremetal avec HAProxy
Rédigé par dada / 20 décembre 2018 / 12 commentaires

Quand on joue avec Kubernetes, on se rend compte que c'est aussi puissant que fragile. L'orchestration, ça ne s'improvise pas. Il faut vraiment passer des heures à se casser les dents sur des clusters de tests qui finiront toujours par s'écrouler. Que ce soit à cause d'un souci côté hébergeur, entraînant une indisponibilité de votre master ou une configuration laxiste permettant à des pods de consommer plus de ressources que ce qu'il y a de disponible, en massacrant chaque node disponible, méticuleusement, les uns après les autres, jusqu'à vous laisser sans rien.
Je ne parlerai pas ici du meilleur moyen pour contrôler la consommation des pods. On va s'attaquer au premier souci : votre unique master configuré en SPoF.
Le multi-master, ton ami
Pour éviter de voir un cluster HS à cause de l'absence de son maître, on va le configurer avec un quorum de... 3 masters. Tout simplement.
Pourquoi HAProxy ?
Mon environnement de test est basé sur des serveurs dans le cloud de Hetzner. J'ai essayé d'attendre aussi longtemps que possible des infrastructures abordables supportant k8s loin des AWS, GCP ou encore Azure, en vain. Il y a bien OVH et DigitalOcean mais le côté "abordable" n'y est pas. Le premier ouvre son infrastructure à partir de 22€ le serveur, et l'autre 20$ (node unique + LB). On est loin des 6€ par machine chez Hetzner.
L'idée
Comme l'indique la documentation officielle, HAProxy va faire ce qu'il sait faire de mieux : rediriger les requêtes. Comment peut-on faire croire à 3 serveurs séparés qu'ils bossent ensemble ? En installant un HAproxy sur chacun d'entre eux, configuré pour loadbalancer les requêtes qui seront balancées sur le 127.0.0.1 et le port 5443 (choisi arbitrairement).
En image, ça donne ça :
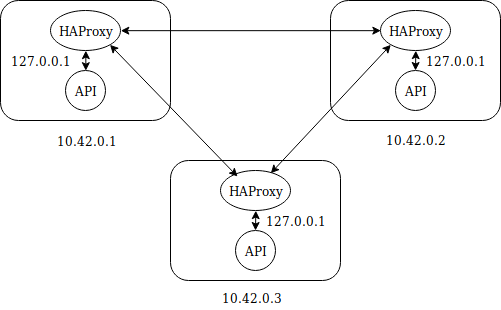
Configurés comme ça, nos masters vont s'amuser entre-eux sans aucun souci.
L'installation
Je passe sur la configuration de Kubernetes, j'en parle déjà ici. Notez quand même que vous pouvez suivre ce que je raconte jusqu'à l'init du cluster. Pas plus. Pourquoi ? Parce que sur le premier de vos masters, nous allons ajouter un fichier de configuration :
root@k8smaster1:~# cat kubeadm-config.yaml
apiVersion: kubeadm.k8s.io/v1beta1
kind: ClusterConfiguration
kubernetesVersion: stable
apiServer:
certSANs:
- "127.0.0.1"
controlPlaneEndpoint: "127.0.0.1:5443"
networking:
podSubnet: "10.244.0.0/16"
Ici, on voit bien que j'ai configuré mon k8s pour taper sur le localhost de la machine à travers le port 5443. C'est là que HAproxy prend la relève.
Je me suis permis d'ajouter la configuration nécessaire à Flannel, mon CNI, qui nécessite en CIDR particulier pour fonctionner correctement. C'est la partie networking.
On peut enchaîner sur la configuration de HAProxy :
global
log /dev/log local0
log /dev/log local1 notice
chroot /var/lib/haproxy
stats socket /run/haproxy/admin.sock mode 660 level admin
stats timeout 30s
user haproxy
group haproxy
daemon
ca-base /etc/ssl/certs
crt-base /etc/ssl/private
ssl-default-bind-ciphers ECDH+AESGCM:DH+AESGCM:ECDH+AES256:DH+AES256:ECDH+AES128:DH+AES:RSA+AESGCM:RSA+AES:!aNULL:!MD5:!DSS
ssl-default-bind-options no-sslv3
defaults
log global
mode tcp
option tcplog
option dontlognull
timeout connect 5000
timeout client 50000
timeout server 50000
errorfile 400 /etc/haproxy/errors/400.http
errorfile 403 /etc/haproxy/errors/403.http
errorfile 408 /etc/haproxy/errors/408.http
errorfile 500 /etc/haproxy/errors/500.http
errorfile 502 /etc/haproxy/errors/502.http
errorfile 503 /etc/haproxy/errors/503.http
errorfile 504 /etc/haproxy/errors/504.http
frontend api-front
bind 127.0.0.1:5443
mode tcp
option tcplog
use_backend api-backend
backend api-backend
mode tcp
option tcplog
option tcp-check
balance roundrobin
server master1 10.0.42.1:6443 check
server master2 10.0.42.2:6443 check
server master3 10.0.42.3:6443 check
La partie global a l'exacte configuration par défaut. J'ai touché à rien.
Dans defaults, j'ai changé le mode de proxy pour le passer de http à tcp.
Les parties frontend et backend regroupent les configurations qui vont bien pour permettre à HAProxy de faire ce que je lui demande. Vous devriez pouvoir recopier tout ça en prenant seulement le soin de changer les IP des masters.
Pour comprendre plus clairement la configuration de HAproxy, je vous redirige vers cet excellent billet de Victor HÉRY.
Une fois configurés, n'oubliez pas de redémarrer les HAProxy sur tous les serveurs et de vérifier qu'ils écoutent bien sur le bon port :
root@k8smaster1:~# nc -v localhost 5443
localhost [127.0.0.1] 5443 (?) open
Astuce : pensez à installer hatop. C'est vraiment super ! Pour le lancer :
hatop -s /var/run/haproxy/admin.sock
Pour le moment, tout sera down, mais une fois le premier master en état, il apparaîtra UP.
On va maintenant initialiser le premier master :
kubeadm init --config=kubeadm-config.yaml
Une fois terminé, vous allez récupérer les informations classiques : le join qui va bien.
kubeadm join 127.0.0.1:5443 --token a1o01x.tokenblabla --discovery-token-ca-cert-hash sha256:blablablablalblawhateverlablablameans --experimental-control-plane
Notez que l'IP de l'API est bien 127.0.0.1 avec le port spécifié à HAProxy. C'est tout bon ! Faites un tour dans hatop et remarquez que le backend du master1 est enfin marqué comme étant UP.
Un get nodes vous confirmera l'arrivée du master1 et un get pods vous montrera les conteneurs de base.
Installons maintenant Flannel, toujours aussi simplement :
kubectl apply -f https://github.com/coreos/flannel/raw/master/Documentation/kube-flannel.yml
Et on aura un premier master en état de fonctionner !
Pour configurer les deux autres masters, il va falloir jouer du SCP. La doc officielle fournit 2 scripts bash que vous pouvez utiliser. Je ne m'étends pas sur le sujet ici et j’enchaîne sur la configuration des autres masters. Pensez quand même à bien configurer SSH et votre user de base.
Une fois que tout est copié, vous n'avez qu'à lancer la commande join sur les masters restant, un par un, et voir le résultat :
dada@k8smaster1:~$ k get nodes
NAME STATUS ROLES AGE VERSION
k8smaster1 Ready master 12h v1.13.1
k8smaster2 Ready master 11h v1.13.1
k8smaster3 Ready master 11h v1.13.1
Ou encore :
dada@k8smaster1:~$ k get pods --all-namespaces
NAMESPACE NAME READY STATUS RESTARTS AGE
kube-system coredns-86c58d9df4-cx4b7 1/1 Running 0 12h
kube-system coredns-86c58d9df4-xf8kb 1/1 Running 0 12h
kube-system etcd-k8smaster1 1/1 Running 0 12h
kube-system etcd-k8smaster2 1/1 Running 0 11h
kube-system etcd-k8smaster3 1/1 Running 0 11h
kube-system kube-apiserver-k8smaster1 1/1 Running 0 12h
kube-system kube-apiserver-k8smaster2 1/1 Running 0 11h
kube-system kube-apiserver-k8smaster3 1/1 Running 0 11h
kube-system kube-controller-manager-k8smaster1 1/1 Running 1 12h
kube-system kube-controller-manager-k8smaster2 1/1 Running 0 11h
kube-system kube-controller-manager-k8smaster3 1/1 Running 0 11h
kube-system kube-flannel-ds-amd64-55p4t 1/1 Running 1 11h
kube-system kube-flannel-ds-amd64-g7btx 1/1 Running 0 12h
kube-system kube-flannel-ds-amd64-knjk4 1/1 Running 2 11h
kube-system kube-proxy-899l8 1/1 Running 0 12h
kube-system kube-proxy-djj9x 1/1 Running 0 11h
kube-system kube-proxy-tm289 1/1 Running 0 11h
kube-system kube-scheduler-k8smaster1 1/1 Running 1 12h
kube-system kube-scheduler-k8smaster2 1/1 Running 0 11h
kube-system kube-scheduler-k8smaster3 1/1 Running 0 11h
Un dernier tour sur hatop pour admirer la présence de tous vos backends enfin marqué UP.
Vous avez maintenant un cluster k8s en HA ! La suite serait peut-être de vous raconter comment sortir ETCd du cluster pour le mettre en place dans un cluster séparé dédié, mais non. Ce billet est déjà bien assez long.
Si tout ne se passe pas comme prévu, pensez à regarder la documentation officielle. Mon billet n'est qu'un complément qui peut contenir des coquilles. Pensez aussi à bien vérifier la configuration de votre firewall, ou encore de HAProxy, ou encore de Docker, ou encore votre VPN parce qu'on ne laisse pas tout traîner sur le réseau. Bref.